af Morten Monrad Pedersen
Indledning
Den første gang jeg hørte om Dean Radins bog “The Conscious Universe” var i november måned sidste år på et internetforum. En af deltagerne i diskussionen på dette forum brugte bogen som bevis for paranormale fænomener. Jeg var en smule skeptisk overfor denne påstand, men tænkte, at det kunne være interessant at se lidt nærmere på bogen. Derfor bestilte jeg den fra min yndlings online boghandel og ventede på, at den nåede frem.
Bogen handler om psi-forskning, dvs. forskning i telepati (tankeoverførsel), clairvoyance (at se ting som ikke kan findes af de almindelige sanser), prekognition (at se ud i fremtiden) og psychokinese (mental påvirkning af fysiske objekter). Radin påstår, at disse fænomener er virkelige, og i bogen præsenteres bevismaterialet, som han mener, beviser dette.
Den første ting, man bør bemærke om denne bog, er, at den ikke er en videnskabelig rapport. Den er derimod læselig for folk uden videnskabelig træning, dog er der nogle tekniske ord, så hvis udtryk som “confidence interval” giver dig hovedpine, så vil det nok være en god ide at have et glas panodiler indenfor rækkevidde.
Den relative høje tilgængelighed af teksten i bogen har den konsekvens, at læserne ikke bliver givet detaljer, og derfor ikke selv kan bedømme, om de resultater, som Radin påstår er blevet opnået, er rigtige eller ej. Dette betyder, at det er af altoverskyggende betydning, at læseren kan stole på, at Radin rapporterer alt fuldstændigt og sandfærdigt.
Dette førte mig til at overveje, hvor troværdig Radin kommer til at se ud efter en grundig læsning af bogen. I denne sammenhæng er jeg bare en lægmand: Jeg ved sikkert lidt mere om statistik end den gennemsnitlige dansker, men jeg er langt bagefter Radin. Jeg ved heller ikke specielt meget om psi-forskning, men nogle af bøgerne på min reol kommer ind på emnet, og jeg har læst lidt om det på nettet.
Hvad kan en lægmand som mig så finde ud af omkring Radins troværdighed ud fra “The Conscious Universe”, bøgerne på min reol og en smule tid med internetsøgemaskinen Google? Dette er, hvad jeg satte mig for at finde ud af, og i denne artikel vil jeg tage dig med på en rejse gennem “The Conscious Universe”.
Rejsen starter med de indtryk, jeg fik fra de første få sider. Der er her ganske vist tale om mindre væsentlige ting, men de fangede min opmærksomhed, og fik mig til at danne en grov skitse af Radin. Hvis du har lyst til at komme til det egentlige indhold i denne artikel kan du simpelhen springe det næste afsnit over.
De første indtryk
Bogen starter med en tak til en række personer, og jeg bemærkede, at Radin i den forbindelse bl.a. betegner Hal Puthoff som et forbillede. Det navn sagde mig noget – var Puthoff ikke den scientologyfyr, som skeptikeren James Randi viste foretog temmelig fejlbehæftet forskning? Dette ledte mig til at bruge Google til at lede efter information om ham, og mine mistanker blev bekræftiget. Puthoff var scientolog, og jeg er personligt temmelig skeptisk overfor den kritiske dømmekraft hos personer, der accepterer scientologygrundlæggeren L. Ron Hubbards fantasifulde historier, og kritisk dømmekraft er essentiel for enhver, der udøver psi-forskning. Endnu vigtigere er det, at scientologyideerne bliver betegnet som videnskab, selv om videnskabsfolk på det kraftigste tager afstand fra dette (se for eksempel http://www.skepdic.com/dianetic.html og Chris Owen: Hysterical Radiation and Bogus Science), så ved at acceptere scientology synes man at smide enhver form for videnskabelig troværdighed overbord. Jeg tog også min udgave af James Randis bog “Flim-Flam!” frem, og det viste sig, at Randi her giver en temmelig hård kritik af Puthoffs forskning. Bl.a. konkluderer han på side 135, at “Kendsgerningerne er klare: Man kan ganske enkelt ikke have tillid til, at Targ og Puthoff kan producere en faktuel rapport ” 1) .
Det er ikke umiddelbart muligt for mig, at afgøre om Randi har ret, og om scientology virkelig er noget vrøvl, men hvis bare en af disse to ting er korrekt, så ville jeg ikke vælge Puthoff som et forbillede for forskere.
I forordet til bogen fortæller Radin en lille historie om et møde, han har haft med to personer i et tog. Disse to personer er meget stereotype. Den ene er en naiv new ager, den anden en uinformeret betonskeptiker. Det jeg lagde mest mærke til ved historien, var den måde, hvorpå de to personer er beskrevet. Indenfor den første halve side fandt jeg følgende:
- “Bjæffede manden”
- “strålende øjne”
- “Enorm glorie af hår”
- “Harry var en reklame for Brooks Brothers”
- “Sagde hun surmulende”
- “rullede med øjnene”
- “stemmen dryppede med sarkasme”
- “Harrys bedrevidende grimasser over livets tåbelighed havde rynket hans pande på en måde, så det lignede en vred flænge. 2)
Jeg kan ikke lade være med at undre mig over, hvorfor Radin føler, at det er nødvendigt at præsentere sådanne karikaturer af to mennesker, der har andre meninger end han selv.
Efter diskussion mellem de to, bliver Radin involveret, og efter kun to sætninger bliver new agerens ansigt beskrevet på følgende måde: “Shirleys ansigt skiftede mellem ærefrygt og forvirring ” 3) . Der skal altså ikke mere end nogle få ord til fra Radin, før hans ‘modstander’ ser på ham med et ansigt, der skifter mellem ærefrygt og forvirring – ganske imponerende.
Efter forordet starter bogen ‘rigtigt’, og Radin fortæller læseren, at “accepten af nye ideer [i videnskaben] følger en forudsigelig, fire-trins sekvens ” 4) . I løbet af beskrivelsen af disse fire trin lykkes det Radin at gøre grin med skeptikere (ved at sige, at de i den fjerde trin siger, at de var de første, der kom på ideen) – hvad, der ikke lykkes ham, er at levere nogen form for støtte for fire-trins modellen. Han gør intet forsøg på at relatere den til eksisterende teorier om videnskab, og han giver ikke nogen eksempler fra videnskabens historie, der følger modellen.
Når jeg tænker på radikale nye ideer i videnskaben, så er de to teorier, jeg som regel tænker på først, relativitetsteori og kvantemekanik, og jeg kan ikke huske, at nogle af kritikerne af disse to banebrydende teorier skulle have udtalt, at de var de første til at komme på ideen (hvilket er hvad Radin påstår, der sker). Dette kan selvfølgelig tænkes at være fordi, jeg ikke ved nok om emnet.
Det forekommer mig, at hvis Radin vil have, at læseren skal tage modellen alvorligt, så burde han levere en eller anden form for dokumentation for den, men det gør han ikke. Derimod bruger han den udokumenterede model til at argumentere for, at mainstream accept af psi-fænomener er på vej (jeg antager her, at han mener mainstream accept indenfor videnskaben).
Det bør retfærdigvis nævnes, at på side 233 og 234 giver Radin faktisk nogle eksempler, der måske støtter hans model, men det er svært at vurdere, for han sammenligner ikke eksemplerne med modellen.
Kreativ citering?
Det rigtige citat på det rigtige sted kan give ekstra vægt til et argument, og Radin bruger en del citater i bogen. Jeg har set nærmere på de første af dem, for at se om Radins brug af dem ser ud til at være korrekt – altså om den måde, han præsenterer dem på, ser ud til at afspejle det, som den citerede person mente.
På side 3 taler Radin om “en fantastisk indrømmelse ” 5) fra astronomen og skeptikeren Carl Sagan i bogen “The Demon-Haunted World”, og han citerer en passage fra denne, hvor Sagan nævner tre påstande indenfor ESP-forskningen, der efter hans mening fortjener seriøs undersøgelse. Radin nævner dog ikke, at lige derefter skriver Sagan det følgende (side 302):
“Jeg vælger ikke disse eksempler fordi jeg tror, at det er sandsynligt, at de er rigtige (det gør jeg ikke), men som eksempler på påstande, der kunne være rigtige. De sidste tre har i det mindste nogen, men stadig tvivlsom, eksperimentel støtte. Men jeg kan selvfølgelig tage fejl .” 6)
Bemærk ordene “det gør jeg ikke”, “kunne” og “tvivlsom”, der gør “indrømmelsen” en hel del mindre “fantastisk”, end Radin gerne vil have os til at tro.
På side 4 og 5 fandt jeg to andre citater. Et af professor i statistik Jessica Utts og et fra professor i psykologi Ray Hyman, der begge har evalueret noget psi-forskning. Utts bliver citeret for det følgende:
“Den statistiske forskning i undersøgelserne vi har undersøgt indtil videre er langt ud over, hvad man kan forvente ved tilfældigheder. Argumenter om, at disse resultater kan skyldes metodefejl i eksperimenter er grundigt afvist. Effekter af størrelsesordener, der ligner dem fra offentligt støttet forskning … er blevet gentaget på flere andre laboratorier verden over. Sådan en konsistens er ikke let at forklare med påstande om fejl eller snyd…. Det anbefales, at fremtidige eksperimenter fokuserer på, hvordan det kan gøres så nyttigt som muligt. Der er ikke meget gavn i at fortsætte med eksperimenter designet til at levere beviser .” 7)
Radin skriver derefter at “overraskende nok var den anden primære bedømmer, skeptikeren Ray Hyman , enig” 8) , og som dokumentation for dette citerer han Hyman:
“De statistiske afvigelser fra tilfældigheder ser ud til at være for store og konsistente til at tillægge til statistiske lykketræf af nogen slags…. Jeg er tilbøjelig til at være enig med Professor Utts i, at der forekommer virkelige effekter i disse eksperimenter. Noget andet end tilfældige afvigelser fra nulhypotesen har forekommet i disse eksperimenter .” 9)
Bemærk venligst de tre ekstra punktummer i Hymancitatet. Jeg tænkte, at det kunne være interessant at finde ud af, hvad det var Radin havde udeladt, så jeg sadlede min trofaste ganger “Google” og tog ud på en eftersøgning af de manglende ord. Jeg fandt rapporten flere steder. Det ene af dem var American Institutes of Research. Det viste sig, at det var de følgende ord, der manglede:
“Selvom jeg ikke kan affærdige muligheden for, at disse afvigelser af nulhypotesen kunne afspejle begrænsninger i den statistiske model som en repræsentation af den eksperimentielle situation ” 10)
Jeg undrer mig over, hvorfor Radin har valgt at udelade dette. Det synes klart, at så tvivl om resultaterne. Hymans rapport indeholder også følgende udtalelse (tak til Claus Larsen for at gøre mig opmærksom på dette):
“Vi er uenige om nøglespørgsmål som:
- Retfærdiggør disse tilsyneladende ikke-tilfældige effekter at konkludere, at eksistensen af unormal kognition er blevet etableret?
- Er muligheden for metodefejl blevet fuldstændigt elimineret?
- Er SAIC resultaterne konsistente med nuværende resultater i andre parapsykologiske laboratorier om remote viewing [der findes vist ikke noget godt dansk udtryk for ‘remote viewing’] og ganzfeldfænomenet
Resten af denne rapport vil forsøge at retfærdigøre, at svarene på disse spørgmål er ‘ nej .'” 11)
Prøv at sammenligne dette citat med Uttscitatet. Når jeg sammenligner dem, så er ordet “enig” ikke det første, jeg kommer på. Det ser altså ud til, at det eneste grundlag Radin har for enigheden er, at Hyman er tilbøjelig til at være enig med Utts om, at det foregår et eller andet, men han synes at være uenig med hende omkring alt andet. Dette bekræfiges yderligere af det følgende citat, som jeg har taget fra Ray Hyman: The Evidence for Psychic Functioning: Claims vs. Reality:
“Jeg tror virkelig ikke, at den ‘aktuelle samling af data’ retfærdiggør, at en anomali af nogen slags er blevet demonstreret, endsige en paranormal anomali. Selvom Utts og jeg – i vores kapaciteter som bedømmere af Stargateprojektet – bedømte de samme datasæt, kom vi til meget forskellige konklusioner .” 12)
Baseret på disse eksempler synes det mig, at Radins måde at bruge, fortolke og udvælge citater er en smule for kreativ, og det giver mig ikke meget tillid til de andre citater senere i bogen (det selvfølgelig ville være at foretrække at undersøge hvert eneste af dem, men det vil være for tidskrævende).
Dommedag
Den første del af denne artikel har handlet om de første få sider i bogen. I de følgende afsnit vil jeg se på nogle andre dele af den, som jeg fandt interessante. Det første jeg vil vende min opmærksomhed imod er Radins beskrivelse af et eksperiment, der blev udført under den direkte tv udsendelse af domsafsigelsen i O.J. Simpson sagen. Før, under og efter denne udsendelse var fem tilfældigtalsgeneratorer (kaldet RNG’er) sat til at producere serier af tilfældige bits. Påstanden bag dette er, at når mange mennesker fokuserer på en ting (i dette tilfælde tv udsendelsen), så påvirker det tilfældige processer som en RNG (dette fænomen kaldes feltbevidsthed).
Radin præsenterer i bogen en graf, der angiver oddsene for, at outputtet fra RNG’erne skyldes tilfældigheder, som funktion af tiden – dette kan anses som et mål for, hvor meget outputtet afviger fra, hvad man vil forvente. Denne graf har jeg modificeret lidt (jeg har tilføjet nogle lodrette linier, så det er lettere at bedømme, præcis hvornår de vigtigste hændelser indtræder) og indsat herunder. Jeg har taget den fra Radins artikel Dean Radin: Where, when, and who is the self?, men til vores formål er den identisk med den i bogen. Det ses, at der er to store toppe, hvor noget rimeligt usandsynligt skete. Det ses yderligere, at grafen ser ud til at indeholde nogle mindre svingninger oven i den overordnede form. Jeg antager, at disse svingninger bare er statistisk støj, som man vil forvente, der er ved en RNG.
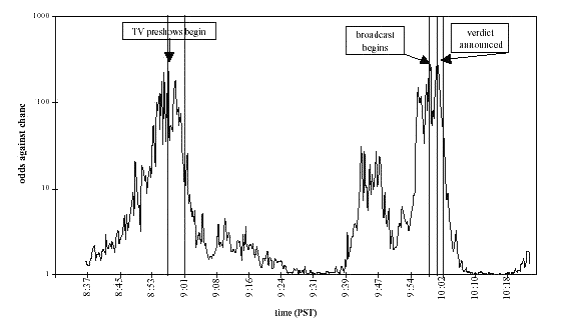
Radin nævner tre begivenheder, der indtræder i løbet af udsendelsen og som han mener er vigtige. Det drejer sig om begyndelsen af optaktsudsendelsen, begyndelsen af selve udsendelsen og domsoplæsningen. Han har markeret disse tre begivenheder på grafen. Radins hypotese er, at der skal være nogle kraftige udslag på grafen samtidig med disse tre begivenheder, og det ser umiddelbart ud til, at det er tilfældet. Ser man lidt nærmere på grafen opdager man dog, at det ikke ser lige så godt ud, som Radin lægger op til.
Pilene, der markerer begivenhederne, på grafen er placeret på toppen af mindre fluktuationer, der ligger oven i grafens overordenede forløb. Dette får det til at se ud som om, at Radin ser betydning i statistisk støj, hvilket for mig synes at være forkert, men på den anden side er det jo Radin, der er statistikeksperten – ikke mig. Så måske er jeg galt på den.
Da pilene på grafen skal symbolisere de tre vigtige begivenheder, burde de markere tidspunkter, der svarer til de tidspunkter, hvor begivenhederne indtræder, men det gør de ikke!
Optaktsudsendelsen skulle ifølge Radin starte 9:00, men på grafen er den sat til at starte et sted mellem 8:56 og 8:57. Faktisk viser grafen, at det udslag på grafen, som Radin mener svarer til starten af optakten, begynder af aftage kl. 9:00. Hvilket er det modsatte af, hvad Radin siger skulle være tilfældet.
Starten af selve udsendelsen skulle ifølge Radin være kl. 10:00, men på grafen er denne begivenhed markeret et sted mellem 9:58 og 9:59.
I forbindelse med selve domsafsigelsen giver Radin den følgende beskrivelse:
“Nogle få minutter senere [det vil sige senere end 10:00] slog alle fem RNG’er ud og nåede det højeste punkt i de to timers dataopsamling, præcis da retsassistenten læste dommen op.” 13)
Nogle få minutter senere end 10:00 kan ikke være før 10:02, men på grafen har Radin markeret domsafsigelsen som om den indtraf omkring 10:00, og udslaget på grafen har påbegyndt sin hurtige forsvinding 10:02.
Disse ting indikerer, at Radin har modificeret timingen på graf, så data kom til at passe til hans teori.
Man kan selvfølgelig komme på flere forskellige forklaringer på disse afvigelser. F.eks. kunne det tænkes, at grafen simpelthen er blevet forskudt lidt langs tidsaksen, men dette synes ikke sandsynligt, da afvigelserne ikke er af samme størrelse. Man kunne også overveje muligheden af, at der er tale om prekognition, men denne mulighed ville gøre andre af Radins eksperimenter ugyldige. Et eksempel på dette er et eksperiment, hvor RNG output blev opsamlet i forbindelse med Oscaruddelingen i 1995. I dette eksperiment indeles udsendelsen af Oscaruddelingen i høj- og lav-interesse dele, og “usandsynligheden” af RNG outputtet for disse dele bliver sammenlignet. Hvis prekognition virkede for feltbevidsthedsfænomenet, så burde man se det mest usandsynlige output før høj-interesse perioderne – det vil sige i lav-interesse perioderne – men dette er ikke tilfældet.
En anden interessant ting, der er værd at lægge mærke til, er, at der er et tredie udslag på grafen, der ganske vist ikke er nær så højt som de to store toppe, men den repræsenterer alligevel en mere usandsynligt hændelse end udslag som Radin regner som værende betydningsfulde i andre lignende eksperimenter (f.eks. i et eksperiment hvor RNG output blev opsamlet under en superbowludsendelse). Dette udslag nævner Radin overhovedet ikke, og ifølge Claus Larsen ( En aften med Dean Radin ) har Radin ikke nogen forklaring på den. Det virker lidt underligt på mig, simpelthen bare at ignorere uforklarede data, der har en størrelsesorden, som man regner som værende signifikant i andre eksperimenter. Hvis jeg var i dårligt humør, så ville jeg nok beskrive dette som at udvælge de data, der passer med teorien, og at ignorere de data, der ikke gør det. Men det er jeg ikke, så det vil jeg ikke gøre.
Kvaliteten af psi-forskning
Psi-forskningen har fået en masse hård kritik gennem meget lang tid. Det er mit indtryk, at Radin underdriver betydningen og relevansen af dele af denne kritik, i det han ikke synes at erkende, at der er blevet fundet fejl i mange eksperimenter, hvor det er blevet tilladt, at nogen har taget et skeptisk kig. Dette er et problem, for mange af de analyser, som Radin har lavet. Han samler nemlig data fra en masse andre menneskers rapporter, og bruger en statistisk metode, der hedder meta-analyse, på disse data, men eftersom han ikke var til stede ved de eksperimenter, der ligger bag rapporterne, så kan han ikke vide, om sikkerhedsforanstaltningerne var så gode som rapporterne siger. For at illustrere problemet ved dette, vil jeg citere en kommentar fra Susan Blackmore (der har en Ph.D. grad i parapsykologi) omkring forskning i de såkaldte ganzfeldeksperimenter:
“Disse eksperimenter, der så så smukke ud på tryk, var i virkeligheden åben for snyd og fejl på mange forskellige måder, og jeg opdagede rent faktisk adskillige fejl og brud på protokollerne, mens jeg var der. Jeg konkluderede, at de udgivne artikler gav et unfair indtryk af eksperimenterne, og at resultaterne ikke kunne bruges som bevis for psi. Til sidst udgav forsøgslederne og jeg selv vores forskellige syn på affæren .” 14)
Dette citat er taget fra Susan Blackmore: What Can the Paranormal Teach Us About Consciousness?. Et andet citat, der kan kaste lidt lys på denne problemstilling er i forbindelse med de såkaldte autoganzfeldeksperimenter, omkring hvilke Ray Hyman har det følgende at sige i artiklen Ray Hyman: The Evidence for Psychic Functioning: Claims vs. Reality:
“Forsøgslederen, der ikke var så godt afskærmet fra senderen, som forsøgspersonen, interagerede med forsøgspersonen under bedømmelsesprocessen. Under halvdelen af forsøgene tilskyndede forsøgslederen faktisk bevidst forsøgspersonen under bedømmelsesproceduren .” 15)
I forbindelse med remote viewing giver James Randi os følgende beskrivelse i bogen “Flim-Flam!” (side 147):
“Bedømmelsesproceduren var blevet designet godt – altså på papiret. Dommerne blev givet en liste med ni steder og en samling afskrifter. Deres opgave var at matche stederne til de korrekte afskrifter. Det blev gjort med stor præcision, og sagen så ud til at være bevist. Men når vi finder ud af, at de tre dommere, der blev udpeget af andre personer fra SRI ikke fik gode resultater med matchingproceduren, begynder vi at blive mistænksomme. Targ og Puthoff [Radins forbillede] fandt derimod to, der var forstående, og disse to gjorde det helt fint .” 16)
Randi fortsætter så med at beskrive, hvordan listen med de ni steder blev givet i kronologisk orden (og dommerne vidste dette), og der var information tilgængelig i afskrifterne, så de også kunne sættes i kronologisk orden. For at dette eksperiment skulle have nogen form for værdi, så var det fuldstændig essentielt, at sådan information ikke var tilgængelig for dommerne, men ifølge Randi, så havde dommerne altså denne viden.
Disse citater illustrerer (hvis man altså kan stole på dem), at eksperimenter kan indeholde fejl, selvom de ser gode ud i rapporterne, og det forekommer mig, at Radin ignorerer dette.
Det er også interessant i denne forbindelse, at Radin nævner parapsykologen J.B. Rhine og hans eksperimenter flere gange uden at fortælle læseren, at det nu vides, at Rhine smed negative data ud fra sine eksperimenter. Fysikeren Robert Park beskriver dette i bogen “Voodoo Science” med de følgende ord (på side 42):
“Rhine troede, at personer, der ikke kunne lide ham, gættede forkert for at trodse ham. Derfor følte han, at det ville være misvisende at inkludere deres resultater .” 17)
Det undrer mig, at Radin har valgt at skrive om mindre ting, som muligheden for, at man kan overføre information ved at mærke konvoluter (der blev brugt til at indeholde kort til ESP tests) ved at ridse dem med ens fingernegle, i stedet for vigtige ting, som svindel (som Rhine dog synes at have udført i god tro).
På side 218 skriver Radin, at:
“Hvis vi var tvunget til at afvise videnskabelige påstande i alle felter, hvor der har været nogle få tilfælde af svindel, så ville vi være nødt til at smide så godt som alle områder af videnskaben ud – for svindels findes i alle menneskelige foretagender .” 18)
Her mener jeg, at Radin misser pointen i kritiken, for det, der er interessant, er ikke, hvorvidt der er snyd og fejl i psi-forskning, men om det er meget mere udbredt end i andre forskningsområder, og om det er ansvarligt for de opnåede resultater.
Et relateret kritikpunkt som Radin også ser ud til at misforstå er illustreret på side 221. Radin fortæller os, at Charles Honorton i 1985 analyserede 28 undersøgelser. 9 af disse var blevet gransket af Susan Blackmore, og hun fandt, at de var klart mærket af fejl (det skal dog bemærkes, at Radin skriver, at hun aldrig har bevist, at disse fejl eksisterede, men det er uvæsenligt for min pointe). Radins kommentar til dette er:
“efter Blackmores påståede ‘fejlfyldte’ undersøgelser” var blevet fjernet fra meta-analysen, var den samlede hit rate i de resterende undersøgelser præcis den samme som før. Med andre ord, Blackmores kritik blev testet og den bortforklarede ikke ganzfeldresultaterne .” 19)
Jeg vil hævde, at Radin igen misser pointen, for hvis de 9 undersøgelser, der faktisk blev set kritisk efter, viste sig at indeholde fejl, hvordan ved vi så, at de andre ukontrollerede undersøgelser ikke gjorde det? Radins argument får mig til at tænke på en fabrik, hvor der bliver taget stikprøver i produktionen, og de viser sig alle at være defekte. Derefter smider man stikprøverne ud og afskiber resten af de producerede varer, for nu har man jo fjernet de fejlbehæftede produkter.
Der er andre tilfælde, hvor jeg ikke føler mig overbevist af Radins forsvar mod kritikken. Et eksempel på dette kan findes på side 136, hvor Radin nævner to ting, som psi-forskere bliver kritiseret for:
1. De lærer ikke af de fejl, som deres forgængere har begået. 2. Effektstørrelserne aftager, når kvaliteten af eksperimenterne stiger.
For at håndtere den først del af denne kritik viser Radin en graf (side 136), hvor kvaliteten af terningekasteksperimenter (forsøg, hvor en testperson skal prøve at påvirke eller forudsige en række terningekast) bliver afbildedet som funktion af tid. Denne graf viser faktisk en stigning i forsøgskvalitet som tiden går, og kunne i første omgang synes at imødegå det første kritikpunkt. Så simpel er situationen dog ikke. En af de første ting, som jeg tænkte, da jeg så grafen var: Hvordan måles kvaliteten af eksperimenterne? Ray Hyman demonstrerer betydning af dette i Ray Hyman: The Evidence for Psychic Functioning: Claims vs. Reality, hvor han skriver, at:
“så vidt jeg kan se, så var jeg den første til at lave en meta-analyse af parapsykologiske data. Jeg lavede en meta-analyse af de oprindelige ganzfeld eksperimenter som en del af min kritik af disse eksperimenter. Min analyse demonstrerede, at visse fejl, specielt kvaliteten af randomiseringen, var korreleret med udfaldet. Succesfulde udfald korrelerede med utilstrækelig metodologi. I sit svar på min kritik lavede Charles Honorton sin egen meta-analyse af de samme data. Han bedømte også for fejl, men han udtænkte bedømmelsessystemer, der var anderledes end mine. I hans analyse korrelerede kvalitetsbedømmelsen ikke med udfaldet. Dette skete bl.a. fordi Honorton fandt flere fejl i usuccesfulde eksperimenter end jeg gjorde. På den anden side fandt jeg flere fejl i succesfulde eksperimenter end Honorton gjorde. Antageligvis troede både Honorton og jeg, at vi bedømte kvaliteten på en objektiv og ufarvet måde. Men alligevel endte vi begge to med resultater, der svarede til vores forudfattede meninger .” 20)
Radin giver en beskrivelse af tretten kriterier, der bruges til at udregne et enkelt kvalitetsmål. Beskrivelsen af hvert kriterie er dog kort, og alternative kriterier eller evalueringsprocedurer bliver ikke diskuteret, så læseren kan ikke rigtig lave en ordentlig bedømmelse omkring grafen. Yderligere mener jeg, at enhver sådan bedømmelse må indeholde subjektive elementer (hvilket også indikeres af Hyman), hvormed man bør tage Radins konklusion med et gran salt. Selvom om vi ignorerer dette problem, så står vi stadig tilbage med det problem, som Blackmore peger på i citatet i begyndelsen af dette afsnit – altså at eksperimenter ikke nødvendigvis er blevet udført som beskrivelserne i rapporterne antyder.
Det andet kritikpunkt svarer Radin på med de følgende ord:
“Vi testede dette argument og så på sammenhængen mellem hit rates (i dette tilfælde gennemsnittet pr. år) og den gennemsnitlige årlige undersøgelseskvalitet. Vi fandt, at sammenhængen essentielt set var flad, så kritikken er ikke gyldig .” 21)
Jeg har et par indsigelser mod dette argument: Hvorfor får vi ikke lov til at se en graf over denne sammenhæng? (Der er tonsvis af grafer i bogen, og dette synes at være en vigtig pointe). Hvorfor får vi ikke at vide, hvor statistisk signifikant resultatet er? (De fleste af resultaterne i bogen er ledsaget af en kommentar om, hvor ‘usandsynlige’ de er, og dermed hvor stor vægt de skal tillægges).
Yderligere er der det problem, at kvaliteten af undersøgelserne er langt fra optimal. Kvalitetsbedømmelsen starter omkring 4 og slutter omkring 7, og så vidt jeg kan finde ud af, så er det på en skala, der går fra 0 til 13, og det har taget 52 år at opnå denne stigning. Dermed kan vi altså konkludere, at selv efter 52 år bryder den gennemsnitlige undersøgelse med ca. halvdelen af kvalitetskriterierne.
På side 142 er der en tilsvarende graf med eksperimentkvalitet som funktion af tid – denne gang for eksperimenter, der drejer sig om at påvirke en RNG. I disse eksperimenter er kvaliteten steget fra ca. 3,5 til 5 på en skala fra 0 til 16 over en periode på 28 år. Det virker ikke som om, at udviklingen er imponerende hurtigt, og det ses altså, at selv efter disse 28 år, så bryder den gennemsnitlige undersøgelse med ca. to trediedele af kvalitetskriterierne, hvilket ikke giver mig den store tillid til de opnåede resultater.
Iøvrigt kan det bemærkes, at grafen på side 142 viser klart lavere kvalitet end grafen på side 136 (og ifølge Radin er kvalitetskriterierne sammenlignelige). Dette lyder måske ikke umiddelbart specielt interessant, men grafen på side 136 er jo for terningekasteksperimenter, og den på side 142 er for RNG-eksperimenter, og ifølge Radin er RNG-eksperimenterne efterfølgere til terningeeksperimenterne (se siderne 138 og 212). Det ses altså, at ‘efterfølgereksperimenterne’ har lavere kvalitet end de eksperimenter, de formodes at være en forbedring af. Dette ser ud til at indikere, at kritikken i hvert fald er delvist korrekt.
En anden interessant ting omkring kritikken af, at psi-effekter aftager med stigende eksperimentkvalitet kan findes på en graf på side 106. På denne graf viser Radin effektstørrelserne for flere forskellige typer af eksperimenter. To af disse er ESP kort-tests og høj-sikkerheds ESP kort-tests. Den ‘normale’ type tests har en effektstørrelse på omkring 65%, mens testene med høj sikkerhed har en effektstørrelse på omkring 55% (50% svarer til, hvad der vil opnås ved tilfældige gæt). Dette viser, at når sikkerheden i kort-tests øges, så falder effektstørrelsen kraftigt. (Til dem der ikke får hovedpine af den slags, kan jeg sige, at 95% konfidensintervallerne for de to effektstørrelser ikke overlapper).
På side 102 (i forbindelse med remote viewing) præsenterer Radin et andet forsvar mod kritikerne, som slår mig som værende underligt:
“I test efter test oversteg psi-formåenen hos en lille gruppe udvalgte individder klart den formåen som ikke-udvalgte frivillige opnåede. Dette var en vigtig observation, for hvis designproblemer var årsagen til succesfulde eksperimenter – som kritkerne antager – så ville den udvalgte gruppe ikke have været i stand til at klare sig bedre end de ikke-udvalgte frivillige deltagere .” 22)
Hvorfor ikke? Vil jeg gerne spørge. Det synes ikke usandsynligt, at nogle få deltagere (udvalgt af forsøgslederne) udnyttede (bevidst eller ubevidst) en eller anden fejl i eksperimenterne, mens resten ikke gjorde det. I tilfælde af svindel er det endnu mere sandsynligt, at nogle få deltagere udvalgt af forsøgslederne vil give de bedste resultater. Hvis jeg var en tryllekunstner, der skulle udføre et tryllenummer, der krævede hjælp af andre personer, så ville jeg klart foretrække at udvælge disse personer selv. Det kan også tænkes, at disse personer snød lige fra starten af, og derfor blev udvalgt af forsøgslederne, der blev imponerede over den store succesrate.
Side 102 indeholder mere interessant information. Bl.a. fortæller Radin læseren, at resultaterne bliver bedre, hvis testdeltagerne fik lov til frit at beskrive, hvad de så i stedet for at være tvunget til at vælge mellem nogle få adskilte muligheder. Dette betyder, at der opnås bedre resultater, når der skulle bruges subjektive bedømmelser, end når en simpel objektiv test anvendes. Når jeg sammenholder dette med James Randis kommentarer om Targ og Puthoffs bedømmelsesprocedurer (se ovenfor), så begynder jeg at blive mistænksom, og det synes mig, at vi igen har et eksempel på, at eksperimenter med høj sikkerhed giver den mindste effekt – præcis som kritikerne påstår.
Radin fortsætter på side 102 med at fortælle, at der også opnås bedre resultater, hvis der gives feedback i løbet af eksperimenterne. Dette sætter også gang i mine alarmklokker, for når man giver feedback, så risikerer man at give testdeltageren information, han ikke burde have haft adgang til (enten verbalt eller via kropssprog), og igen ser det for mig ud som om, at når man strammer op på sikkerheden (her ved at udelukke kommunikation med testdeltageren), så falder effektstørrelsen.
Hvis vi fortsætter på side 240, så kan vi se, at Radin har endnu en interessant måde at håndtere sine kritikere på:
“Intet omkring hverken Gellers eller Randis arbejde er beskrevet i denne bog. De er faktisk så irrelevante for videnskabelig vurdering af psi, at ikke et eneste eksperiment, der involverer nogen af dem er inkluderet blandt de tusinder undersøgelser, der er blevet gennemgået i meta-analyserne. ” 23)
Radin behøver altså bare at sige, at kritikerne er irrelevante, så kan han tillade sig at ignorere dem. Jeg må sige, at det meget tidsbesparende i forhold til at give sig til at argumentere for, at der er noget galt med Randis kritik.
I denne forbindelse kan det måske være interessant at bemærke, at den anden irrelevante person Uri Geller (der påstår, at han har psykiske krafter) faktisk var den centrale forsøgsperson i nogle eksperimenter udført af Radins forbillede Hal Puthoff, og der kom endda en videnskabelig artikel ud af det.
Forsøgsdesign
Jeg vil nu prøve at se lidt nærmere på designet af nogle få af de eksperimenter, som Radin var involveret i, og jeg vil starte med at se på feltbevidsthedseksperimenter – altså eksperimenter hvor man ser på “usandsynligheden” af output fra en (eller flere) RNG(er), når mange mennesker fokuserer på den samme ting. Jeg har allerede omtalt O.J. Simpson tv-udsendelseseksperimentet, som er et eksempel på et feltbevidsthedseksperiment.
På side 165 beskriver Radin et eksperiment, hvor to fra hans forskerstab bragte en bærbar computer og en RNG til et komik- og hypnoseshow. Under showet inddelte en af forskerne showet i to typer af perioder: Dem der var af høj interesse, og dem der var af lav interesse, og det blev så checket om RNG outputtet var mere “usandsynligt” i høj-interesse perioderne, end det var i lav-interesse perioderne. Det viste sig, at dette var tilfældet, men det bekymrer mig, at forskeren, der lavede inddelinger i høj- og lav-interesse perioderne, måske havde adgang til RNG outputtet undervejs. Radin fortæller os ikke, om forskeren havde det eller ej, og det virker underligt for mig, for det er meget væsentligt for eksperimentets troværdighed, fordi hendes egne forventninger (bevidst eller ubevidst) kan komme til at farve hendes inddeling. Dette er et velkendt fænomen, der kaldes experimenter bias.
Experimenter bias kan også have været et problem i forbindelse med et forsøg afviklet under tv-udsendelsen af Oscar uddelingen i 1995. I dette forsøg var det Radin og en assistent, der lavede en inddeling i høj- og lav-interesse perioder. Jeg undrer mig over, at Radin ikke har valgt at lade en udenforstående lave denne inddeling, netop for at sikre sig, at anklager om data manipulation og experimenter bias kunne afvises på dette punkt.
Jeg undrer mig også over, at i de feltbevidsthedseksperimenter som Radin beskriver i bogen, ser det ud som om, at han har ændret forsøgsdesignet mellem eksperimenterne. Nogle gange laves en tidsopdeling i høj-interesse og lav-interesse perioder, andre gange gøres dette ikke, og atter andre gange bruges et mere komplekst tal for, hvor interessant noget er. Det ser også ud til, at han nogle gange bruger akkumulerede odds, og at han andre gange ikke gør det. Hvorfor laver Radin disse designændringer? Det bliver jo langt sværere at sammenligne resultaterne, og det gør påstande om reproducerbarhed mindre troværdige. Det gør også forsøgene sårbar overfor kritik, som f.eks. spekulation om, at forsøgsdesignet er blevet valgt efter dataopsamlingen, for at opnå de mest gunstige resultater.
Jeg vil nu midlertidigt forlade feltbevidsthedseksperimenterne og fortsætte til det kapitel i bogen, der strækker sig over siderne 175 til 189. Dette kapitel handler om psi og hasardspil, og Radin præsenterer en masse grafer, der viser korrelationer mellem Månens cyklus og gevinstudbetalinger fra kasinoer og lotterier. Dette er muligvis interessant, men det første spørgsmål, som jeg ville stille i forbindelse med psi og hasardspil, er ikke: Er mængden af gevinstudbetalinger relateret til Månens cyklus? I stedet ville jeg have overvejet om gevinstudbetalinger fra enarmede tyveknægte er højere end forventet (fordi de bliver påvirket af psi)? Hvorfor er Radin pludselig interesseret i korrelationer med Månens cyklus? Hvordan kan han vide, at det ikke er astrologi han tester i stedet for psi? Hvorfor var han ikke interesseret i Månens cyklus i forbindelse med alle de andre psieksperimenter? Hvis jeg var af en mere mistænksom natur, ville jeg måske foreslå, at Radin fokuserer på Månens cyklus i denne sammenhæng, fordi han ikke kunne finde nogen psieffekter i stil med dem han fandt i de andre typer af eksperimenter.
Det virker som om, at Radin faktisk ikke mener, at Månen påvirker udbetalingerne, men at dens cyklus i stedet er korreleret med en faktor, der gør det. Han foreslår to sådanne faktorer:
- Det geomagnetiske felt (GMF).
- Tyngdekraften.
Hvis Radin mener, at det er disse faktorer, der er de afgørende, så fatter jeg ikke, hvorfor alle hans grafer (bortset fra en) relaterer sig til månens cyklus i stedet for GMF og tyngdekraft. Problemet bliver gjort værre af, at nogle gange er GMF positivt korrelerettil Månens cyklus (side 187), og nogle gange er den negativt korreleret (side 182). Det synes at være en lidt indviklet måde at tackle problemet om en sammenhæng mellem GMF og psi på.
Radins begrundelse for at teste sammenhængen mellem tyngdekraft og psi via Månens cyklus er det følgende (side 180):
“En måde at gøre dette på var at udføre et eksperiment hver dag i løbet af månens cyklus, fordi sol-måne systemet ændrer tyngdekrafterne (altså tidevandskrafterne), der mærkes på jorden, på en forudsigelig måde .” 24)
Det virker på mig som en meget ineffektiv måde at teste tyngdeeffekter på. Jeg ville foreslå, at man udførte eksperimenter på forskellige tidspunkter af dagen, for tyngdepåvirkningerne fra Sol-Måne systemet varierer meget mere over en dag, end den gør over en Månecyklus. Som vi alle ved er tidevandsændringerne et dagligt ikke et månedligt fænomen. Derfor burde det have været muligt at måle en meget større effekt hvis eksperimentet havde været udført på denne måde.
Testene for korrelation mellem GMF og gevinstudbetalinger er som nævnt lavet ved at se efter korrelationer mellem Månens cyklus og kasinogevinstudbetalinger. Som sagt er Radins begrundelse for dette, at der er en korrelation mellem Månens cyklus og GMF. Dette er dog problematisk, da korrelationen nogle gange er positiv og nogle gange negativ. Dette gør mig temmelig forvirret, for hvis jeg skulle teste for en korrelation mellem to fænomener X og Y, så ville jeg lave en direkte test for dette. Radin gør i stedet det, at han finder et fænomen Z, der ser ud til at være korreleret på en kompliceret måde til X, og så ser han om der er en korrelation mellem Y og Z. Radins metode ser ud til at gøre sagen unødigt kompliceret og gør det svært at komme til nogen rimelig konklusion.
Hvis GMF virkelig er vigtig for psi, så burde placeringen af laboratorier være vigtig for psi-eksperimenter, for så vidt jeg ved, så varierer GMF fra sted til sted på Jorden. Soludbrud burde også tages i betragtning, for de ser ud til at give de stærkeste påvirkninger på GMF (see Committee on Solar and Space Physics: Space Weather: A Research Perspective – tak til Mogens Winther for dette link).
Det virker yderligere som om dette kapitel, som Radin kalder “Psi i kasinoet”, burde have heddet “Månen i kasinoet”, eftersom det hovedsageligt indeholder tests for korrelationer mellem gevinstudbetalinger og Månens cyklus. Jeg kan ganske enkelt ikke se, hvorfor dette er bevis for psi. Hvorfor er det ikke bevis for astrologi eller hypotesen, at det geomagnetiske felt påvirker enarmede tyveknægte?
Det undrer mig også, at det i et tilfælde er sådan, at en korrelation mellem Månens cyklus og et fænomen indikerer en sammenhæng mellem fænomenet og tyngdekraften, og i andre tilfælde indikerer en korrelation mellem et fænomen og Månens cyklus en sammenhæng mellem fænomenet og GMF. Dette forekommer mig at være inkonsistent.
Som jeg nævnte i indledningen, så er jeg sikker på, at Radin ved langt mere om statistik end jeg gør. Alligevel er der nogle statistiske emner, som jeg gerne vil omtale. Det første emne jeg vil komme ind på, er den statistiske metode, der hedder meta-analyse. Det er en metode, hvor man analyserer en masse undersøgelser sammen. Radin bruger denne metode meget, og den er meget vigtig for hans argumentation, men den er blevet kraftigt kritiseret, f.eks. af Ray Hyman (Ray Hyman: The Evidence for Psychic Functioning), der skriver:
“at drage konklusioner fra meta-analyse undersøgelser er som at blæse og have mel i munden .” 25)
Og statistikeren og astrofysikeren Jeffrey Scargle skriver det følgende om Radins brug af meta-analyse i “The Conscious Universe” (Jeffrey Scargle: Publication Bias (The “File-Drawer Problem”) in Scientific Inference):
“Muligheden for at disse resultater er tilfældige og skyldes publication bias bliver overvejet og så forkastet [af Radin] fordi FSFD beregninger giver enorme værdier for den formodede arkivskuffe. Jeg mener, at for de her beskrevne grunde, så er disse værdier meningsløse og publication bias kan godt være ansvarlig for de positive resultater afledt af de kombinerede undersøgelser .” 26)
Scargle bruger her udtrykket “kombinerede undersøgelser” i stedet for meta-analyse, og med “publication bias” (som jeg ikke kender noget dansk udtryk for) mener han, at det ofte kun er eksperimenter, der har givet positive resultater, der bliver publiceret, mens negative resultater forbliver i arkivskuffen. Dette bliver illustreret af det følgende citat taget fra James Randis bog “Flim-Flam!” (side 143):
“Hundreder af eksperimenter, der blev udført af SRI mens de testede Price, Geller og Swann, blev aldrig rapporteret. I stedet blev tests med positivt udfald udvalgt, på trods af deres dårlige kontroller og stærkt farvede tvetydighed, til publicering som ægte videnskabelige resultater på trods af kraftige protester fra mere seriøse og forsigtige videnskabsfolk .” 27)
Jeg har ikke nogen tilstrækkelig viden til at bedømme om Radin har ret eller ej, men Scargles argumenter lyder rimelig for mig.
Jeg vil efterlade meta-analyse spørgsmålet uafklaret og gå videre til et andet statistisk begreb: Konfidensintervaller. Hvis du har en række målinger af en eller anden størrelse, så kan du beregne gennemsnitsværdien af disse målinger, men du kan ikke være sikker på, at den gennemsnitsværdi du kommer frem til svarer til den virkelige værdi. Lad os tage et eksempel:
Forestil dig, at du vil finde ud af, om amerikanere i gennemsnit er højere end danskere. For at gøre dette måler du højden af 1000 amerikanere og 1000 danskere, og beregner gennemsnitshøjderne for de to grupper. Du kan dog ikke være sikker på, at de beregnede gennemsnitsværdier svarer til de virkelige befolkningsgennemsnit, derfor kan du bruge en statistisk metode til at beregne et interval for hver af de to gennemsnit. Denne metode sikrer, at du er 95% sikker på, at befolkningsgennemsnittet er indenfor dette interval. Et sådant interval kaldes et 95% konfidensinterval. Hvis konfidensintervallerne for de to gennemsnit overlapper, så kan vi ikke være sikre på, at den ene befolkning i gennemsnit er højere end den anden, men hvis de f.eks. ikke overlapper og det amerikanske gennemsnit er højere end det danske, så kan vi være rimeligt sikre på, at amerikanere faktisk er højere end danskere i gennemsnit.
Radin bruger 95% konfidensintervaller på de fleste af sine grafer (og det er også den normale statistiske praksis), men af en eller anden grund skifter han til 65% konfidensintervaller i nogle af dem (f.eks. på siderne 102-124 og 182-185), hvilket betyder, at vi ikke kan stole nær så meget på de konklusioner, der opnås ud fra disse grafer. Det virker underligt, at Radin vælger at være inkosistent på denne måde, og det er interessant at bemærke, at han bruger 65% konfidensintervaller på de grafer, hvor forskellen mellem tallene ikke er særlig store. Ved kun at bruge 65% konfidensintervaller disse steder får Radin resultaterne til at se mere overbevisende ud end de i virkeligheden er. Ved mange af graferne kan vi ganske enkelt ikke have særlig stor tiltro til, at de viser noget som helst andet end tilfældige variationer. Radins skift til 65% virker endnu mere mærkeligt i lyset af, at han på side 35 selv fremhæver 95% kriteriet.
Ikke nok med, at der nogen steder bliver brugt 65% konfidensintervaller, så er der også steder, hvor der overhovdedet ingen konfidensintervaller bliver givet (f.eks. side 181 og 187), og det bliver derfor umuligt at afgøre, og man kan konkludere noget som helst ud fra disse grafer.
Mens vi er ved grafen på side 181 (som viser en forbindelse mellem Månens cyklus og ESP evner), så vil jeg nævne, at der ikke bliver givet noget data for en eller to dage lige omkring fuld måne. Dette virker meget underligt, for det burde vel netop være disse dage, der er de vigtigste i eksperimentet. Så hvorfor er disse dage udeladt? Og nedsætter det ikke værdien af grafen ganske betragteligt? Jeg undrer mig over, at Radin overhovedet ikke kommeterer dette problem.
Jeg vil også gerne gøre opmærksom på. at grafen, der viser en korrelation mellem Månens cyklus og kasino gevinstudbetalinger i perioden 1991 til 1994 viser en positiv korrelation. Et par sider længere fremme præsenterer Radin en graf, der viser en korrelation mellem Månens cyklus og gevinstudbetalinger fra lotteri i 1993. Denne gang er korrelationen dog negativ. Dette generer dog ikke Radin, og han fortæller os, at dette skyldes, at i 1993 var der en positiv korrelation mellem Månens cyklus og GMF, hvilket er det omvendte af den normale situation. Denne information slog mig dog som værende temmelig underlig, for 1993 er jo netop et af de år, der er inkluderet i kasinoundersøgelsen. Hvorfor har korrelationerne modsat fortegn, hvis de er fra undersøgelser, der overlapper hinanden i tid? Jeg undrer mig over, at Radin ikke ser ud til at bemærke dette problem.
Feltbevidsthedseksperimenterne, som jeg har omtalt nogle gange, rejser yderligere spørgsmål. For det første, så vil jeg nævne, at i en graf på side 166 plotter Radin akkumulerede RNG odds som funktion af tiden for både høj- og lav-interesse perioder i det komik-/hypnoseshow, som jeg tidligere har omtalt (der er en kurve for høj-interesse perioderne og en kurve for lav-interesse perioderne). Høj-interesse kurven stiger stille og roligt fra lave til relativt høje odds. Radin skriver i denne forbindelse det følgende:
“Store fluktuationer som disse kan forekomme i kortere tilfældige sekvenser, men fortløbende akkumulering af sådanne odds over længere sekvenser er ikke så sandsynligt. Det er derfor, at langtidstendensen af data mens de bliver akkumuleret indenfor hver betingelse er af interesse snarere end øjeblikkelige fluktuationer ” 28)
Lav-interesse kurven forbliver ved lave odds hele tiden, men den er meget kortere end høj-interesse kurven (der var åbenbart færre mindre interessante perioder i showet), og høj-interesse kurven er næsten lige så lav som lav-interesse kurven i hele sidstnævntes udstrækning. Hvordan kan Radin så konkludere, at der virkelig er en forskel på oddsene i de to kurver?
Det ovenstående citat er også interessant på en anden måde, for Radin skriver, at øjeblikkelige fluktuationer kan forekomme pga. af tilfældigheder, og at man derfor skal bruge akkumulerede odds. I O.J. Simpson eksperimentet bruger han dog ikke akkkumulerede odds. Han går altså direkte imod, det han selv siger. I denne sammenhæng skal det også bemærkes, at i showeksperimentet ignorerer Radin et udslag, der ca. når odds 1 til 1000, og har en varighed på ca. 10 minutter, men i O.J. eksperimentet tillægger han stor betydning til et udslag, der ca. når odds 1 til 300 (bemærk, at skalaen på grafen er logaritmisk) og har en varighed på ca. 8 minutter. Ud fra Radins egne argumenter burde man faktisk ignorere samtlige resultater opnået i O.J. Simpson eksperimentet.
Er psi et konsistent fænomen?
Jeg mener, at det er meget interessant at undersøge, om psi ser ud til at være et konsistent fænomen, og Radin kommer med nogle kommentarer omkring dette. Et eksempel på dette ses i forbindelse med et eksperiment, hvor en person forsøger at påvirke kast med en terning (side 141):
“Vi ser, at terningeundersøgelsesresultaterne og RNG undersøgelsesresultaterne er bemærkelsesværdigt ens, hvilket antyder, at de samme bevidsthed-materie interaktionseffekter er blevet observeret gentagne gange”
“We see that the dice study results and the RNG study results are remarkably similar, suggesting that the same mind-matter interaction effects have been repeatedly observed”
Jeg kan dog ikke se, hvorfor vi skulle forvente de samme effektstørrelse i disse to typer af eksperimenter. En RNG er trods alt temmelig forskellig fra en terning. Med lad os føje Radin og acceptere, at vi skal forvente ensartede effektstørrelser i forskellige eksperimenter. Det virker så temmelig underligt, at Superbowl feltbevidsthedseksperimentet gav odds, der er næsten 100 gange lavere end i feltbevidsthedseksperimentet fra Oscaruddeling i 1995, og hvorfor opnås der langt lavere odds under Oscaruddelingerne fra 1996 end for 1995 uddelingen? Det virker helt ærligt ikke særlig konsistent.
I forbindelse med et eksperiment, hvor RNG data blev optaget under en olympiade åbningsceremoni, fortæller Radin, at hele ceremonien var af høj interesse, men ikke desto mindre er oddsene meget lave i den første halvdel af eksperimentet, mens i O.J. Simpson eksperimentet argumenterede Radin for, at der blev opnået betydende resultater med det samme noget spændende skete. Hvorfor tager det to timer at opnå betydende resultater i olympiadeeksperimentet, mens der sker øjeblikkeligt i O.J. eksperimentet?
Tilsvarende indikerer det faktum, at oddsene skifter mellem høj- og lav-interesse perioder i Oscareksperimentererne, at der burde være øjeblikkelige effekter, men som nævnt er dette ikke tilfældet i olympiadeeksperimentet. Det kan også undre, at oddsene ikke falder til et lavt niveau øjeblikkeligt efter åbningsceremonien slutter, når dette ser ud til at være, hvad der sker i de andre eksperimenter.
Hvis vi sammenligner effektstørrelserne i superbowl- og olympiadeeksperimenterne, så ser vi, at superbowleksperimentet giver meget lavere odds end olympiadeeksperimentet. Radin skriver, at dette er fordi, der ikke er særlig stor forskel mellem høj- og lav-interesse perioder under superbowl, fordi det hele går så hurtigt, og selv reklamepauserne er åbenbart interessante. Dermed kan vi konkludere, at hvis alt er interessant, så vil man ikke opnå høje odds. Desværre bedømmes hele olympiade åbningsceremonien ifølge Radin som værende interessant, men alligevel bliver der opnået høje odds – det synes heller ikke at være særlig konsistent.
Hvorfor bemærker Radin slet ikke disse inkonsistenser?
Der er flere inkonsistenser i Radins resultater og argumenter. I forbindelse med feltbevidsthedseksperimenterne skriver Radin (på side 161), at forsøg på at fokusere på at påvirke RNGer kan ødelægge effekten på RNGen. Men så vil jeg gerne vide, hvordan eksperimenterne, hvor et menneske bevidst skal forsøge at påvirke en RNG, kan fungere? Disse to ting synes at modsige hinanden, men det ser Radin ikke ud til at bemærke.
På side 173 skriver Radin, at han har antaget, at den globale bevidsthedseffekt er “ikke-lokal, hvilket betyder, at den ikke vil aftage med afstand ” 29) . Kombinerer vi dette med det faktum, at 40 mennesker, der ser et komik/hypnoseshow kan producere betydelige effekter, så når vi den konklusion, at RNGer altid burde give betydende resultater, for det er svært at forestille sig, at der ikke til hver en tid foregår et eller andet interessant, der involverer 40 mennesker et sted på Jorden. I virkeligheden har vi dog ikke hele tiden betydende resultater fra RNGer, så Radins antagelse ser ud til at være modsagt.
Yderligere skal det bemærkes, at hvis feltbevidsthed er ikke-lokal, så burde den vel påvirke andre psi-eksperimenter, hvor en person f.eks. skal påvirke en RNG. Hvis man skal tage ikke-lokal feltbevidsthed alvorligt, så forekommer det mig, at man så er nødt til at tage højde for den i alle andre psi-eksperimenter, men det gør Radin ikke.
Det er også interessant at overveje konsekvenserne af de eksperimenter, som Radin synes at mene etablerer en forbindelse mellem tyngdekraft og ESP. Tyngdekraftfluktuationerne i dette eksperiment skyldes ændringer i Sol-Måne systemet i løbet af Månens cyklys, men som jeg har argumenteret for tidligere, så skifter tyngdekrafter mere i løbet af et døgn, end den gør hvis man ser på et fast tidspunkt hver dag i løbet af en Månecyklus. Så hvis tyngdekraften har nogen indflydelse, så burde tidspunktet på dagen have en meget større indflydelse på psi-krafter end Månens cyklus. Derfor burde tidspunktet på dagen betragtes som en meget betydende faktor i psi-eksperimenter, men det ser ud som om, at der aldrig er nogen, der har taget højde for dette. Den geografiske placering af en laboratorium burde også være betydende, da tyngdekraften er stærkere ved ækvator, end den er ved polerne, men denne faktor synes også at blive ignoreret. Der er også lignende problemer i forbindelse med Månens cyklys og GMF.
Som en sidste bemærkning omkring konsistent vil jeg gerne nævne, at på side 102 siger Radin, at i forbindelse med remote viewing klarer nogle få forsøgspersoner sig meget bedre end resten, og dette er også tilfældet for prekognition (se side 115), men i forbindelse med bevidstheds-materie interaktioner skriver Radin, at der ikke er nogen, der klarer sig markant bedre end andre. Der kan selvfølgelig være en fuldstændig naturlig forklaring på dette, men det slår mig ikke som værende en egenskab ved et konsistent fænomen.
Afsluttende bemærkninger
Jeg lider ikke under den illusion, at mine skriblerier her vil få nogen til at afvise den forskning, der bliver præsenteret i “The Conscious Universe” – dette har aldrig været min intention, og efter min mening er “The Conscious Universe” en interessant bog, hvis emne fortjener nærmere undersøgelser. Hvad jeg har prøvet at gøre i denne artikel er at vise, at der ser ud til at være nogle fejl og mangler i bogen, som jeg mener er værd at huske på, når man evalurer den. Jeg påstår ikke, at jeg har fundet den absolutte sandhed om noget som helst, men det, jeg har skrevet, er resultatet af mine overvejelser om det Radin skriver. Eftersom menneskelige overvejelser sjældent er perfekte (og min mangel på perfektion er blevet demonstreret mange gange) vil jeg sætte pris på det, hvis du kontakter mig, hvis du finder en fejl i denne artikel, eller i det hele taget har kommentarer til mig .
Til sidst vil jeg gerne sige tak for din opmærksomhed, og tak til Dann Simonsen og Henrik Mølgaard Hansen for hjælp med oversættelserne.
Citaterne på originalsproget
1 “The record is clear: Targ and Puthoff just cannot be trusted to produce a factual report”.
2 “Barked the man”, “luminous eyes”, “immense halo of hair”, “Harry was an advertisement for Brooks Brothers”, “she said pouting”, “rolled his eyes”, “voice dripping with sarcasm” og “Harry’s smirk at life’s stupidity had permanently creased his forehead with an angry gash”.
3 “Shirley’s face wavered between awe and bewilderment”.
4 “the acceptance of new ideas [in science] follows a predictable, four-stage sequence”
5 “an astonishing admission”
6 “I pick these claims not because I think they’re likely to be valid (I don’t), but as examples of contentions that might be true. The last three have at least some, although still dubious, experimental support. Of course I could be wrong.”
7 “The statistical research of the studies we examined are far beyond what is expected by chance. Arguments that these results could be due to methodological flaws in the experiments are soundly refuted. Effects of similar magnitudes to those found in government-sponsored research … have been replicated at a number of laboratories across the world. Such consistency cannot be readily explained by claims of flaws or fraud…. It is recommended that future experiments focus on how to make it as useful as possible. There is little benefit to continuing experiments designed to offer proof”
8 “Surprisingly, the other principal reviewer, skeptic Ray Hyman, agreed”
9 “The statistical departures from chance appear to be too large and consistent to attribute to statistical flukes of any sort…. I tend to agree with Professor Utts that real effects are occurring in these experiments. Something other than chance departures from the null hypothesis has occurred in these experiments.”
10 “Although I cannot dismiss the possibility that these rejections of the null hypothesis might reflect limitations in the statistical model as an approximation of the experimental situation”
11 “We disagree on key questions such as:
1. Do these apparently non-chance effects justify concluding that the existence of anomalous cognition has been established?
2. Has the possibility of methodological flaws been completely eliminated?
3. Are the SAIC results consistent with the contemporary findings in other parapsychological laboratories on remote viewing and the ganzfeld phenomenon
The remainder of this report will try to justify why I believe the answer to these three questions is ‘no.'”
12 “Indeed, I do not believe that ‘the current collection of data’ justifies that an anomaly of any sort has been demonstrated, let alone a paranormal anomaly. Although Utts and I — in our capacities as coevaluators of the Stargate project — evaluated the same set of data, we came to very different conclusions.”
13 “a few minutes later [that is later than 10:00] the order in all five RNGs suddenly peaked to its highest point in the two hours of recorded data precisely when the court clerk read the verdict.”
14 “These experiments, which looked so beautifully designed in print, were in fact open to fraud or error in several ways, and indeed I detected several errors and failures to follow the protocol while I was there. I concluded that the published papers gave an unfair impression of the experiments and that the results could not be relied upon as evidence for psi. Eventually the experimenters and I all published our different views of the affair”
15 “The experimenter, who was not so well shielded from the sender as the subject, interacted with the subject during the judging process. Indeed, during half of the trials the experimenter deliberately prompted the subject during the judging procedure.”
16 “The judging procedure had been well designed-on paper, that is. Judges were given a list of nine locations and a package of transcripts. Their job was to match the locations with the correct transcripts. It was done with great accuracy, and the case seemed proved. But when we find that three judges appointed by other officials at SRI failed to get good results with the matching procedure, we begin to get suspicious. Targ and Puthoff [Radin’s role model], however, found two who were symphathetic, and these two did just fine.”
17 “Rhine believed that persons who disliked him guessed wrong to spite him. Therefore, he felt it would be misleading to include their scores.”
18 “if we were forced to dismiss scientific claims in all fields where there have been a few cases of experimenter fraud, we would have to throw out virtually every realm of science-since fraud exists in all human endeavors.”
19 “after Blackmore’s allegedly ‘marred’ studies were eliminated from the meta-analysis, the overall hit rate in the remaining studies remained exactly the same as before. In other words, Blackmore’s criticism was tested and it did not explain away the ganzfeld results.”
20 “As far as I can tell, I was the first person to do a meta-analysis on parapsychological data. I did a meta-analysis of the original ganzfeld experiments as part of my critique of those experiments. My analysis demonstrated that certain flaws, especially quality of randomisation, did correlate with outcome. Successful outcomes correlated with inadequate methodology. In his reply to my critique, Charles Honorton did his own meta-analysis of the same data. He too scored for flaws, but he devised scoring schemes different from mine. In his analysis, his quality ratings did not correlate with outcome. This came about because, in part, Honorton found more flaws in unsuccessful experiments than I did. On the other I found more flaws in successful experiments than Honorton did. Presumably, both Honorton and I believed we were rating quality in an objective and unbiased way. Yet, both of us ended up with results that matched our preconceptions.”
21 “We tested this argument by looking at the relationship between hit rates (in this case, averaged by year) and the study quality averaged per year. We found that the relationship was essentially flat, so the critique is not valid.”
22 “in test after test, psi performance among a small group of selected individuals far exceeded performance among unselected volunteers. This was an important observation, because if design problems accounted for successful experiments-as critics often assumed-then the selected group would not have been able to perform consistently better than unselected volunteers.”
23 “nothing about the work of either Geller or Randi is described in this book. They are actually so irrelevant to the scientific evaluation of psi that not a single experiment involving either person is included among the thousand studies reviewed in the meta-analyses.”
24 “One way to do this was to conduct an experiment every day over the lunar cycle, because the sun-moon system predictably changes the gravitational forces (i.e., tidal forces) felt on earth.”
25 “drawing conclusions from meta-analytic studies is like having your cake and eating it too.”
26 “The possibility that these results are spurious and due to publication bias is considered, and then rejected [by Radin] because the FSFD calculations yields huges values for the putative file drawer. It is my opinion that, for the reasons described here, these values are meaningless and that publication bias may well be responsible for the positive results derived from combined studies.”
27 “Hundreds of experiments that were done by SRI in testing Price, Geller and Swann were never reported. Instead, tests with favorable results were selected, in spite of their poor control and heavily biased ambiguity, to be published as genuine scientific results despite strenuous objections from more serious and careful scientists.”
28 “Large fluctuations like this may occur by chance in shorter random sequences, but progressive accumulation of such odds over longer sequences is not as likely. This is why the long-term trend of the data as they are accumulated within each condition is of interest, rather than momentary fluctuations”
29 “non-local, meaning that it would not drop off with distance.”
Kilde: Skeptic Report, February 2003
[*]


Seneste kommentarer